DDUC & Aerial Video Greenery Indexing
Overview
This project bridges advanced road-scene semantic segmentation with actionable urban analytics. We implemented the Dual Dense Upsampling Convolution (DDUC) architecture from a recent 2024 ICCEA paper to parse highly complex, high-resolution environments, and then extended its application to the RuralScapes aerial video dataset.
The ultimate goal was not just to segment pixels, but to build a pipeline capable of dynamically calculating the Proportion of Vegetation Green View Index (PVGVI) across continuous video streams.
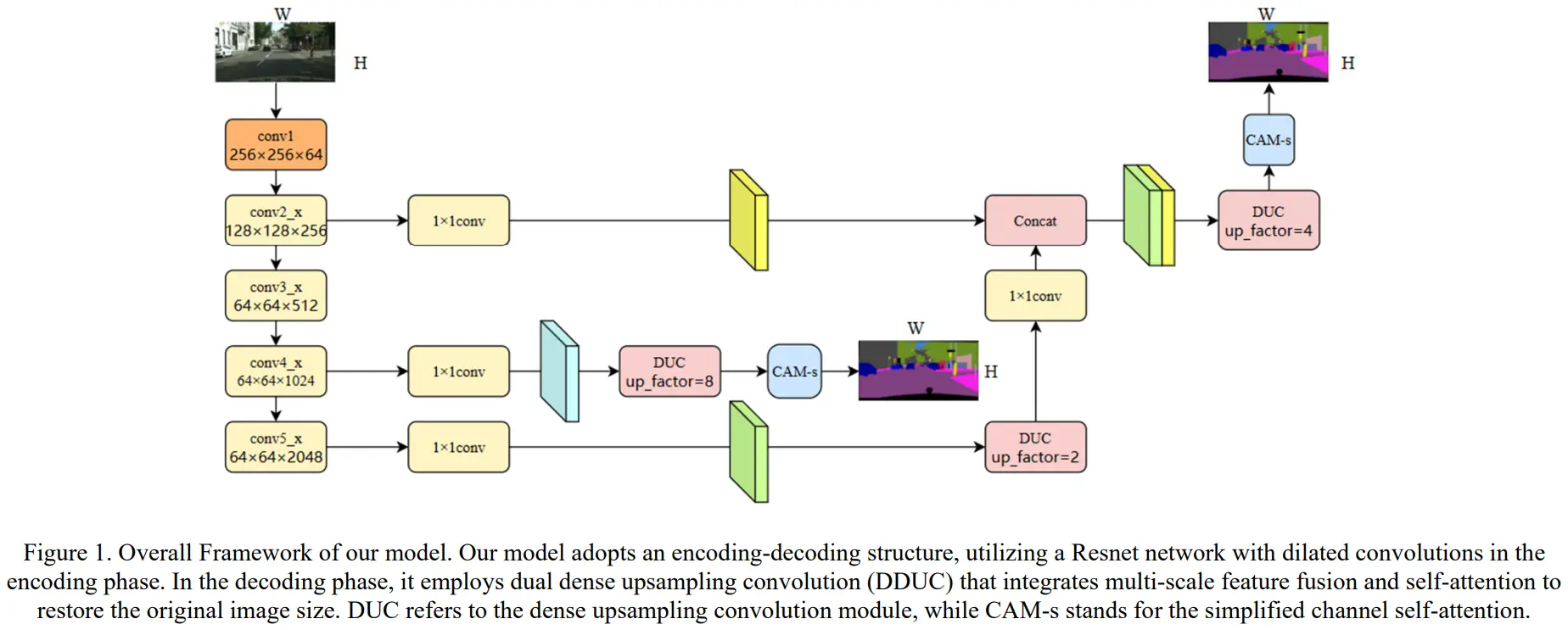
The Architecture: DDUC vs Standard Upsampling
Standard segmentation networks (like UNet or DeepLab) often struggle with small, distant objects (e.g., traffic lights) or boundary blurring between visually similar classes like roads and grasslands. This is typically due to information loss during standard transposed convolutions or bilinear upsampling.
DDUC solves this by employing a dual-path upsampling mechanism. It simultaneously preserves high-frequency spatial details and deep semantic context, allowing the network to maintain enhanced discriminative capabilities even on obscured or truncated targets.
The Core Engineering: The PVGVI Video Inference Pipeline
Training the model locally on CityScapes required standard PyTorch optimizations like Automatic Mixed Precision (AMP) and hard-example cropping. However, the primary engineering challenge was the temporal video inference phase.
High-resolution aerial video (1080p) causes massive GPU memory spikes during dense pixel-wise classification. We implemented a sliding-window inference technique to chunk the frames, process them through the DDUC model, and reassemble the logits.
Following segmentation, a custom Python pipeline parsed the resulting matrices frame-by-frame to aggregate specific biological class IDs (e.g., trees, terrain) against the total pixel count. This allowed us to programmatically isolate the frame with the highest PVGVI (Green Index), translating raw model tensors directly into a usable urban planning metric.
# Extracting and aggregating the PVGVI metrics during video inference
summ_fields = [
'video',
'highest_pvgvi_frame','highest_pvgvi_value','highest_pvgvi_unique_classes',
*(f'highest_pix_{k}' for k in green_ids),
'most_classes_frame','most_classes_unique_classes','most_classes_value',
*(f'most_pix_{k}' for k in green_ids)
]
summary = {
'video': video_base,
'highest_pvgvi_frame': best_gvi['frame_idx'],
'highest_pvgvi_value': best_gvi['gvi'],
'highest_pvgvi_unique_classes': best_gvi['unique_classes'],
**{f'highest_pix_{k}': best_gvi[f'pix_{k}'] for k in green_ids},
'most_classes_frame': best_cls['frame_idx'],
'most_classes_unique_classes': best_cls['num'],
'most_classes_value': best_cls['gvi'],
**{f'most_pix_{k}': best_cls[f'pix_{k}'] for k in green_ids}
}
# Output serialized to CSV for downstream urban analysis dashboardsSample Inference Results



Repository
- GitHub: View Source Code Here