Tweets Sexism Detection (NYCU-NLP)
Overview
This project was an empirical study of three system implementations for sexism detection in tweets, published in the working notes of CLEF 2025 (Madrid, Spain). We focused on an “Annotator-Aware” approach, operating under the LeWiDi (Learning with Disagreements) paradigm, realizing that sexism is highly subjective and heavily dependent on the demographic lens of the labeler.
We engineered and compared three distinct architectures:
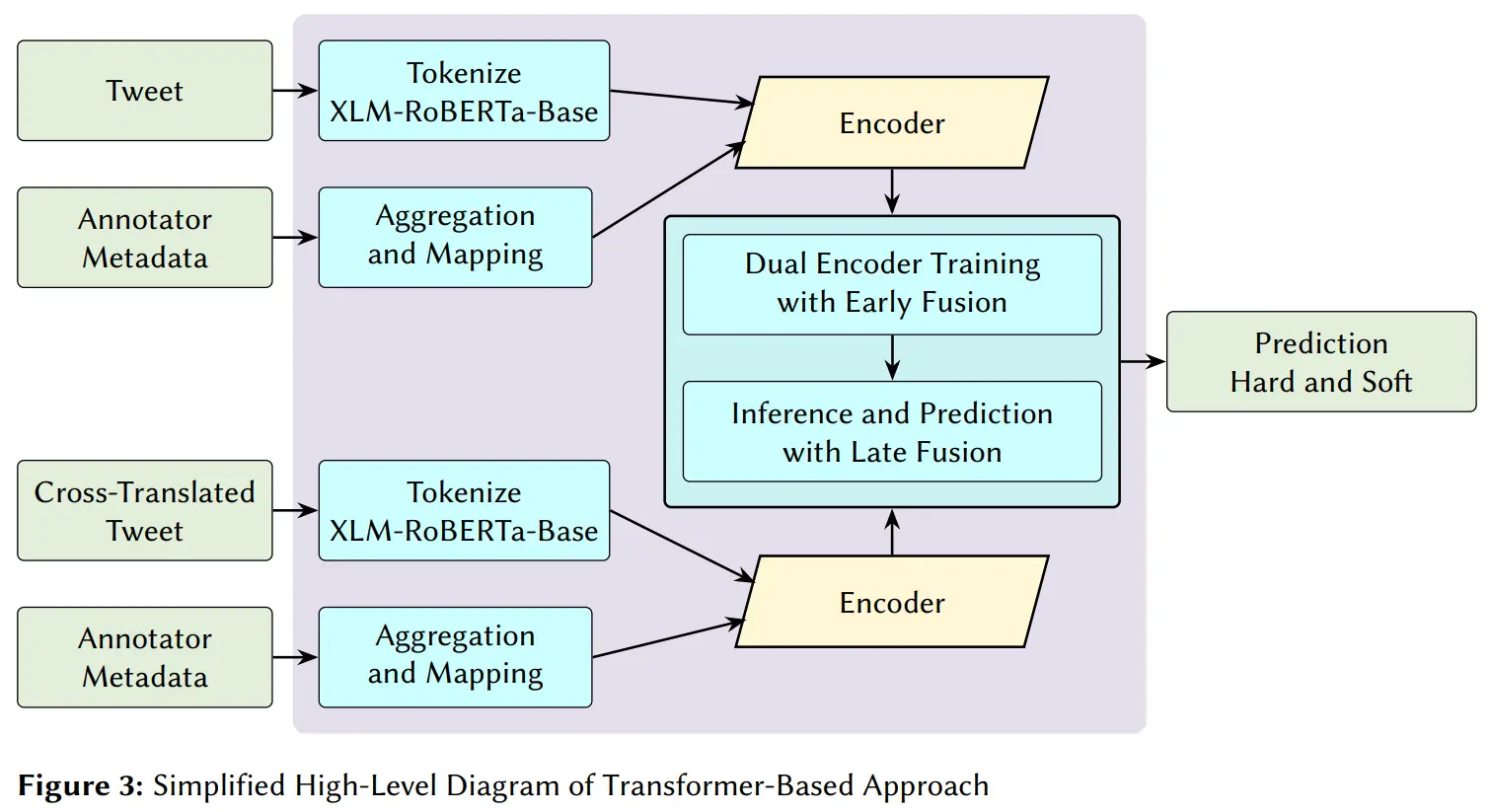
- Fine-tuned Transformer-based (XLM-RoBERTa): Utilizing early and late fusion techniques.
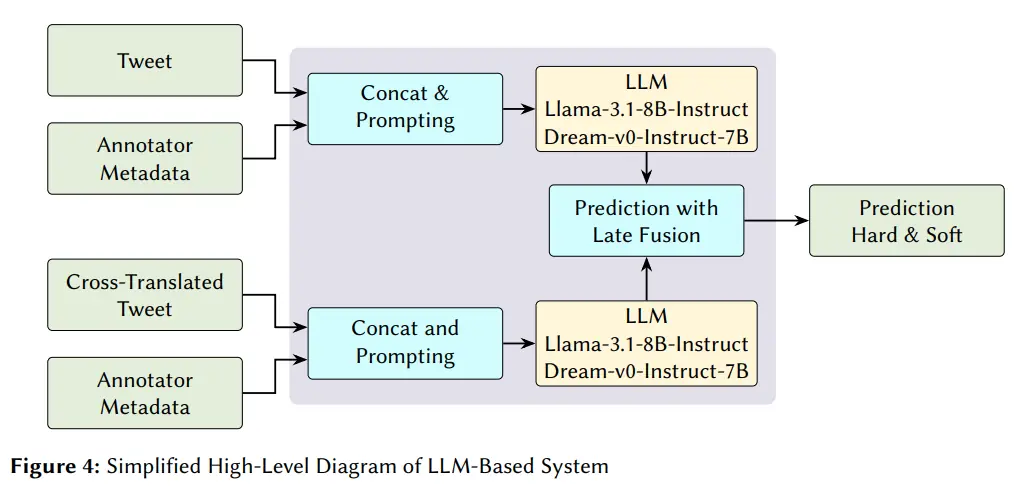
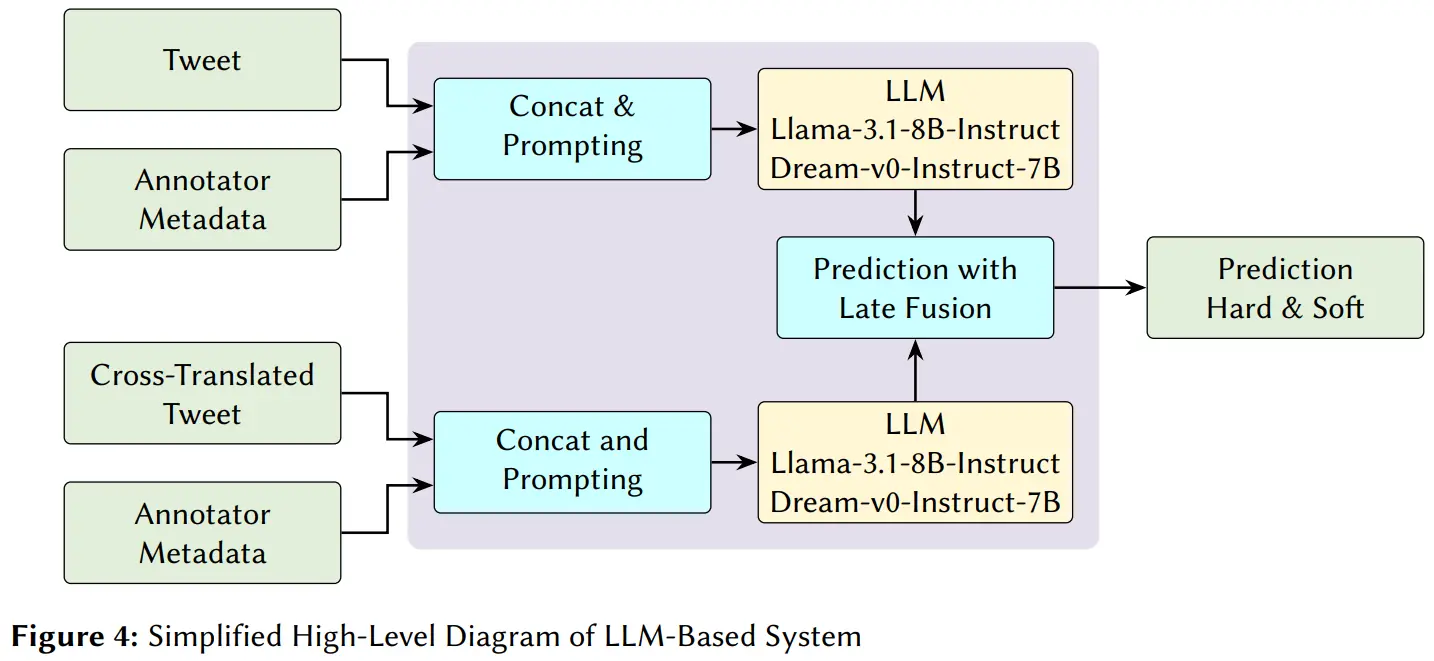
- Zero-shot Auto-Regressive (AR) LLM: LLaMA-3.1-8B-Instruct.
- Zero-shot Diffusion LLM: Dream-v0-Instruct-7B.
Key Architecture Features:
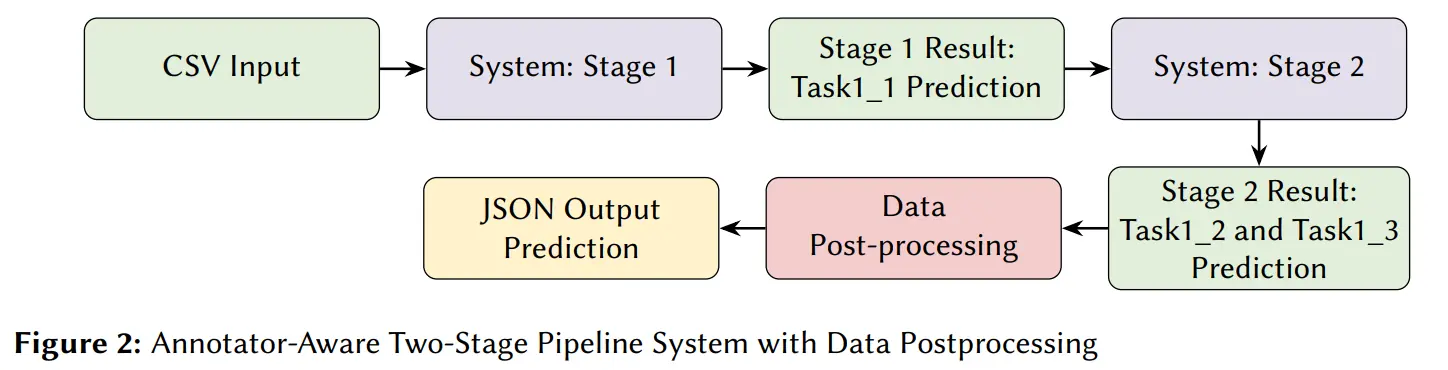
- Two-Stage Pipeline: All systems follow a hierarchical process: Stage 1 filters for sexism presence (binary), and Stage 2 classifies misogynistic intent (multi-class) and sexism category (multi-label).
- Bilingual Fusion: We combined original tweets with cross-translated versions to capture linguistic nuances and mitigate translation artifacts.
- Demographic Integration: We explicitly injected annotator demographics (Age, Gender, Ethnicity, Education, Country) into the models to account for subjective bias.
The ‘Annotator-Aware’ Engineering Problem
The core technical challenge was mapping diverse, subjective human demographics into a mathematical format the models could use to weight their predictions. We solved this using two distinct approaches depending on the model architecture.
1. Transformer Approach (Embedding & Multi-Head Attention)
For the XLM-R system, we engineered a custom AnnEncoder in PyTorch. We mapped the categorical demographics into dense embeddings, concatenated them, and passed them through a Multi-Head Attention (MHA) layer. This yielded a 32-dimensional metadata summary which was then concatenated directly with the text’s [CLS] token.
class AnnEncoder(nn.Module):
def __init__(self, n_country, n_ethnic, n_study, emb_country=8, emb_ethnic=8, emb_gender=4, emb_study=4, age_dim=4, ann_dim=32, n_heads=4):
super().__init__()
self.gender_emb = nn.Embedding(2, emb_gender)
self.country_emb = nn.Embedding(n_country, emb_country)
self.ethnic_emb = nn.Embedding(n_ethnic, emb_ethnic)
self.study_emb = nn.Embedding(n_study, emb_study)
self.age_lin = nn.Linear(1, age_dim)
in_dim = emb_gender + emb_country + emb_ethnic + emb_study + age_dim
self.mlp = nn.Sequential(nn.Linear(in_dim, ann_dim), nn.ReLU())
self.attn = nn.MultiheadAttention(ann_dim, num_heads=n_heads, batch_first=True)
def forward(self, gender, country, ethnic, study, age):
ge = self.gender_emb(gender.long())
ce = self.country_emb(country.long())
ee = self.ethnic_emb(ethnic.long())
se = self.study_emb(study.long())
ae = self.age_lin(age.unsqueeze(-1))
x = torch.cat([ge, ce, ee, se, ae], dim=-1)
x = self.mlp(x)
o, _ = self.attn(x, x, x)
return o.mean(1)2. LLM Approach (Prompt Injection)
For the zero-shot LLaMA and Diffusion models, demographic embeddings could not be natively concatenated. Instead, we dynamically generated structured context prompts, aggregating the data of all six annotators per tweet before querying the LLM for log probabilities.
# Constructing the metadata prompt for zero-shot LLM injection
meta = "; ".join(
f"Ann{j}: gender={row[f'gender_annotators_{j}']},"
f" country={row[f'countries_annotators_{j}']},"
f" ethnicity={row[f'ethnicities_annotators_{j}']},"
f" study={row[f'study_levels_annotators_{j}']},"
f" age={row[f'age_annotators_{j}']}"
for j in range(1, 7)
)
prompt_o = f"{meta}\nTweet: \"{row['tweet']}\"\nQ: Does this contain misogyny?\nA: "Results and Performance
All models were evaluated on the CLEF 2025 development and test sets. The table below highlights the Macro F1 scores across the three tasks on the development set.
| Task | System 1 (Transformer) | System 2 (AR LLM) | System 3 (Diffusion LLM) |
|---|---|---|---|
| Task 1_1 (Binary Detection) | 0.8053 | 0.6728 | 0.6722 |
| Task 1_2 (Intent Classification) | 0.5121 | 0.2706 | 0.2640 |
| Task 1_3 (Fine-grained Category) | 0.3135 | 0.2717 | 0.2402 |
Analysis:
The fine-tuned Transformer dual-encoder architecture dominated the zero-shot LLMs across all tasks.
The LLM systems were constrained by in-context learning without task-specific weight updates. Conversely, the Transformer system, through backpropagation over our custom AnnEncoder, actively learned how to weigh the specific demographic nuances of the annotators against the linguistic features of the text.
However, it is notable that the novel Diffusion LLM (System 3) performed essentially on par with the standard Auto-Regressive LLM (System 2), demonstrating the viability of diffusion models for complex text classification pipelines.
Publication
- Title: NYCU-NLP at EXIST 2025: An Empirical Study of Annotator-Aware Two-Stage Pipeline for Sexism Detection in Tweets
- Authors: Joy Chrissetyo Prajogo, Lung-Hao Lee, and Hsien-I Lin
- Conference: Working Notes of CLEF 2025, Vol 4038, pp. 2119-2132.
- DOI / Link: CEUR-WS Vol-4038 Paper 164
Repository
- GitHub: View Source Code Here